Do you claim 100% accuracy?
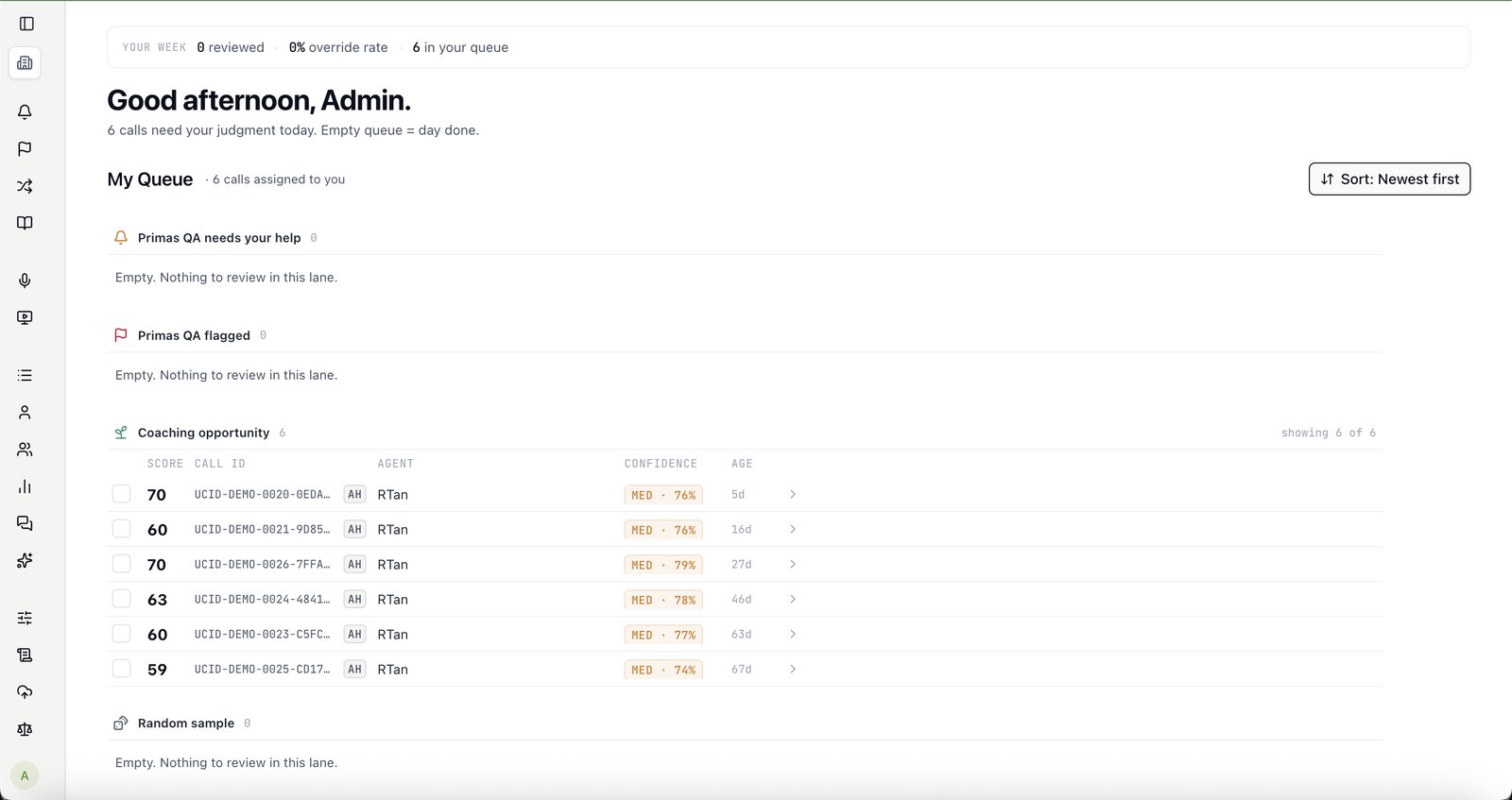
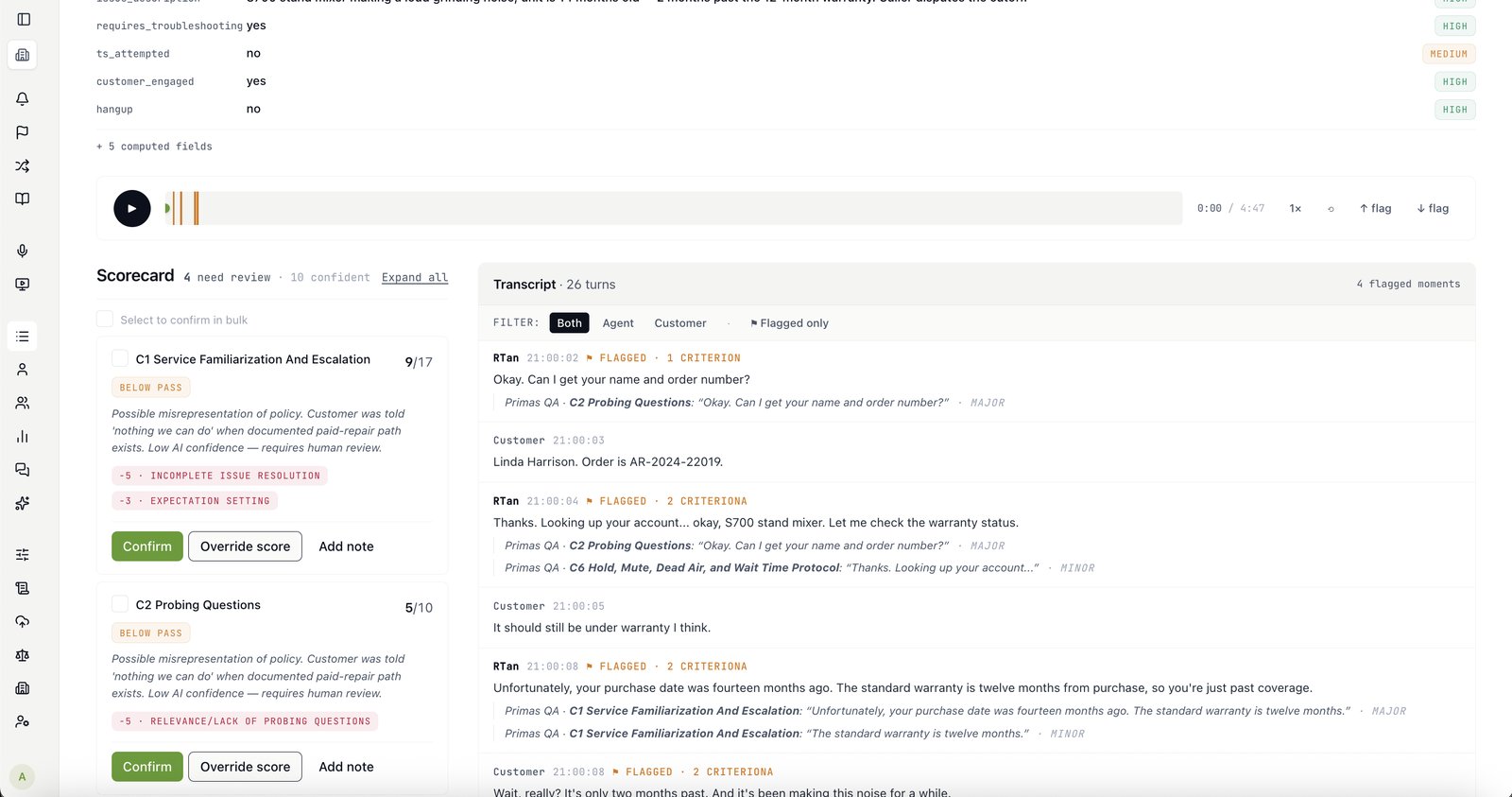
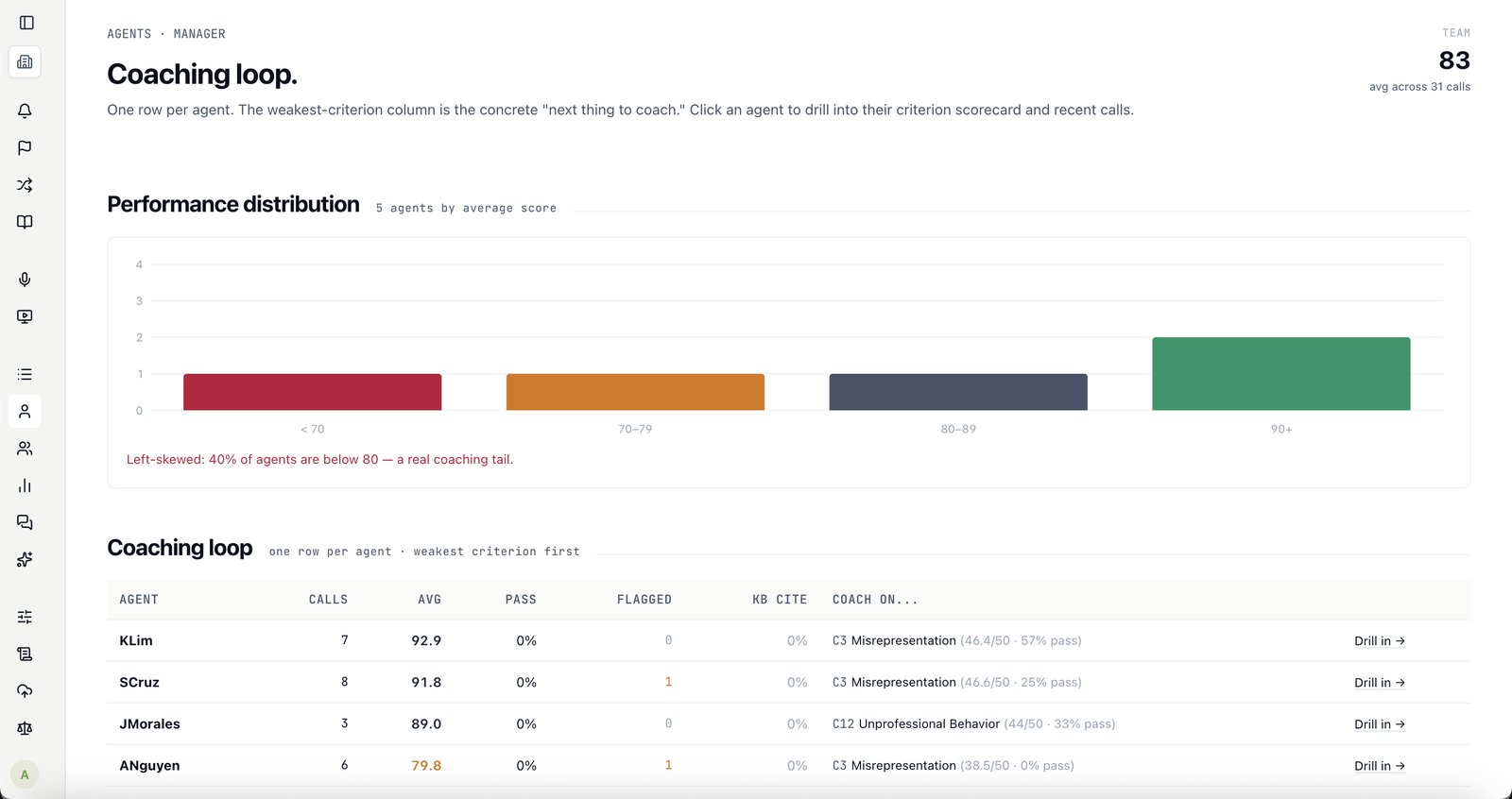
No — and that's the point. We give every score a confidence number and tell you exactly where the AI is sure and where it isn't. High-confidence calls auto-confirm; the uncertain ones go to a human. An honest system you can defend beats a "100% accurate" black box you can't.
Is Primas call center quality assurance software or conversation intelligence software?
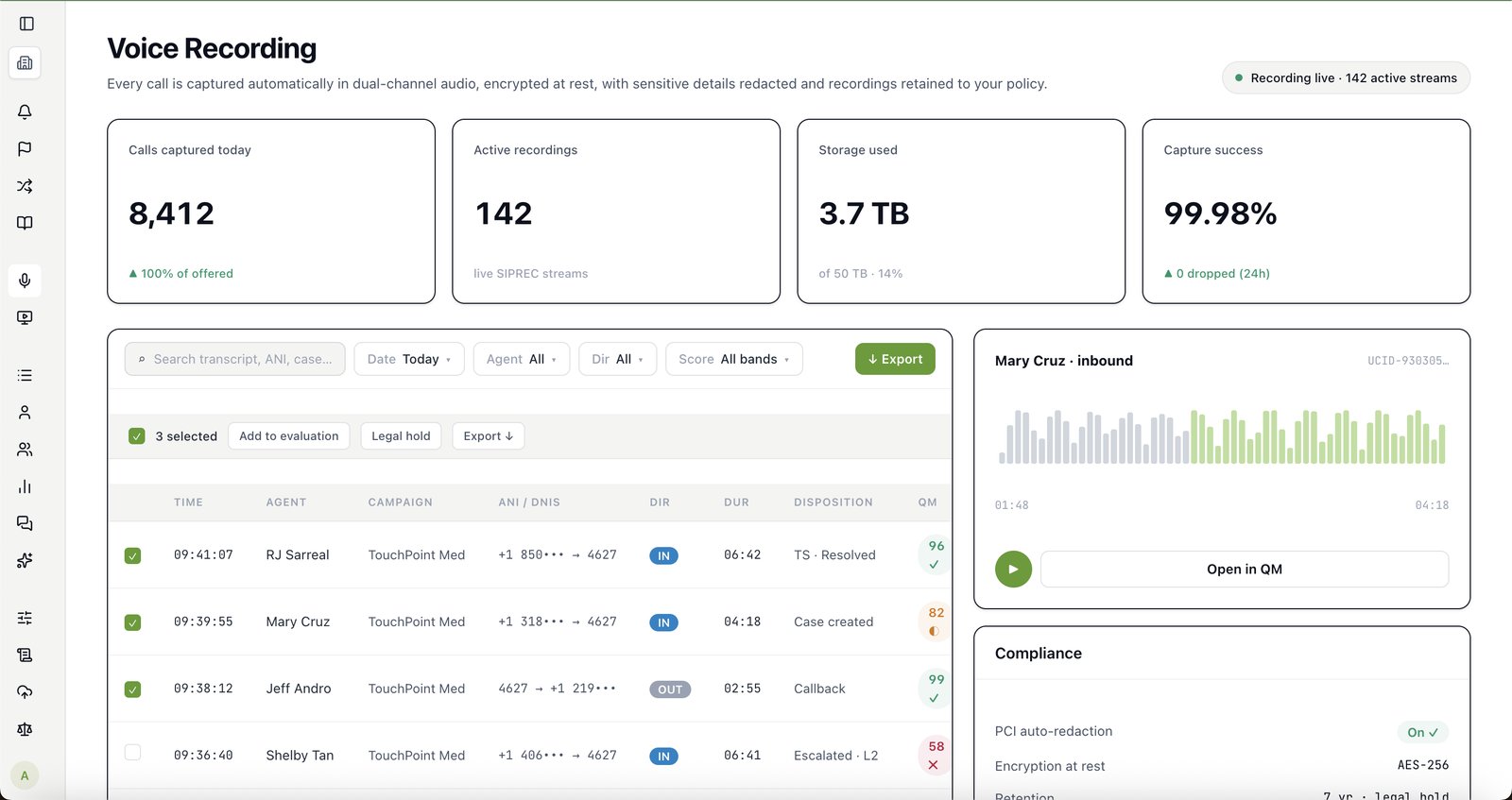
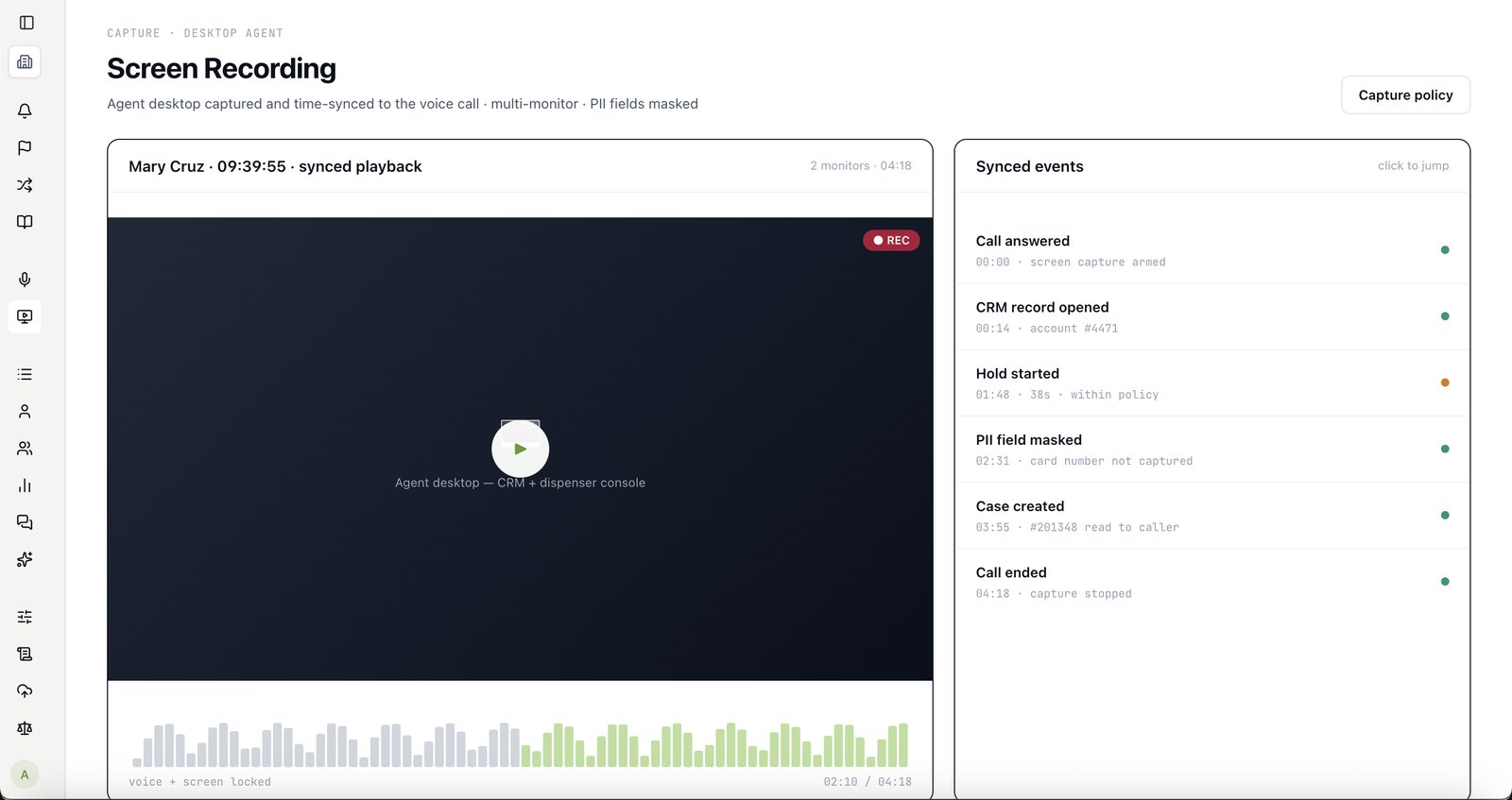
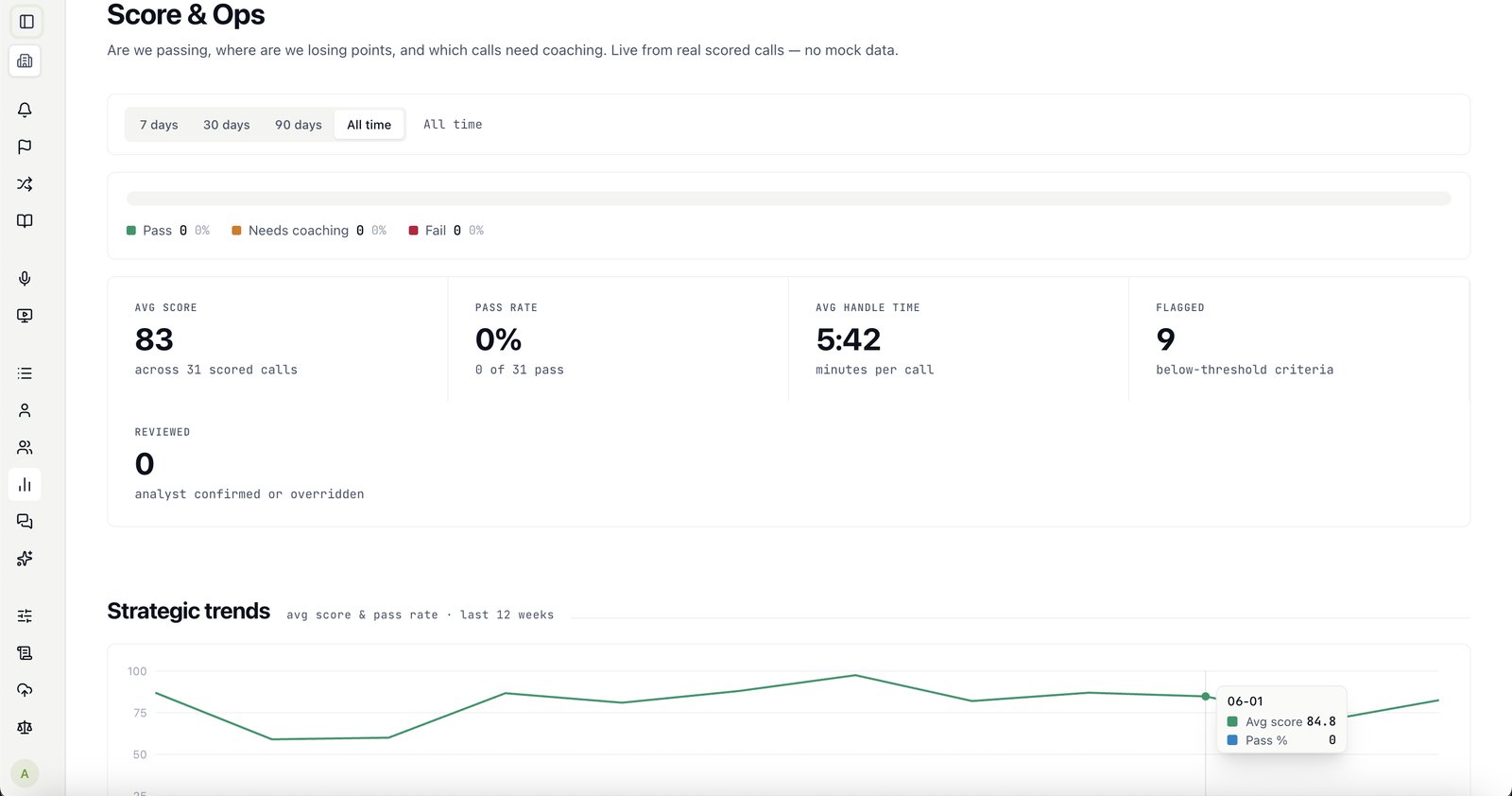
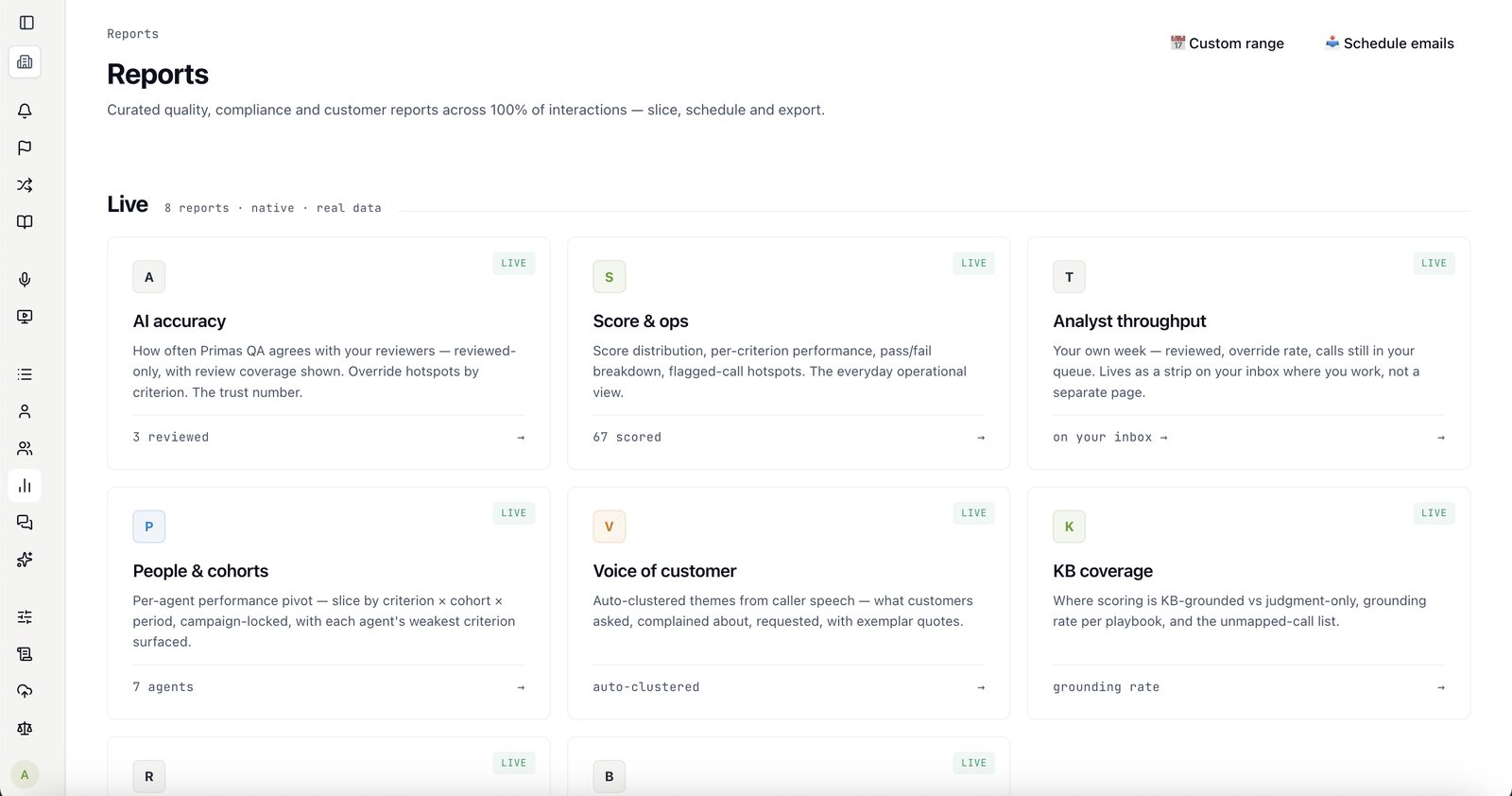
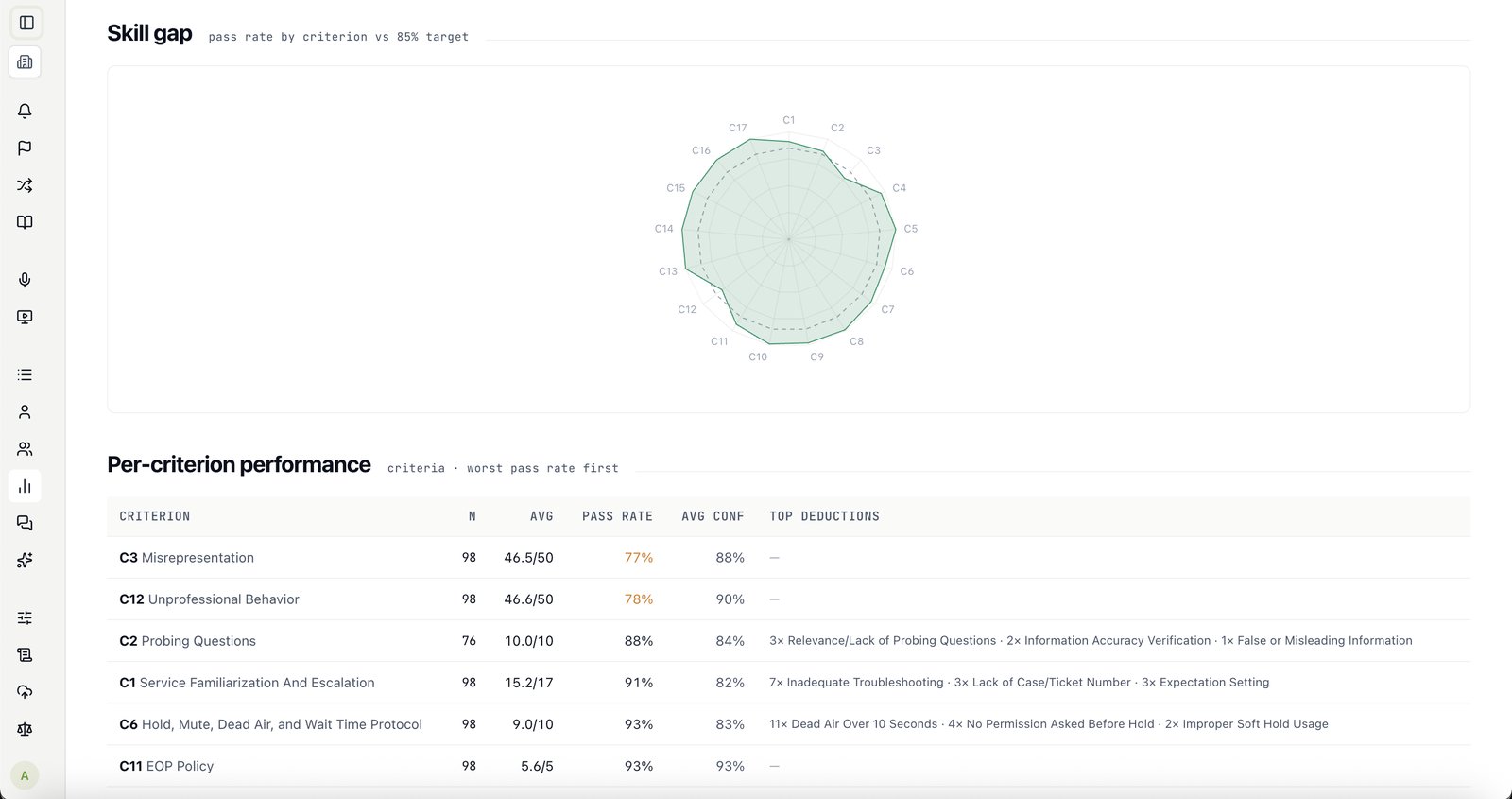
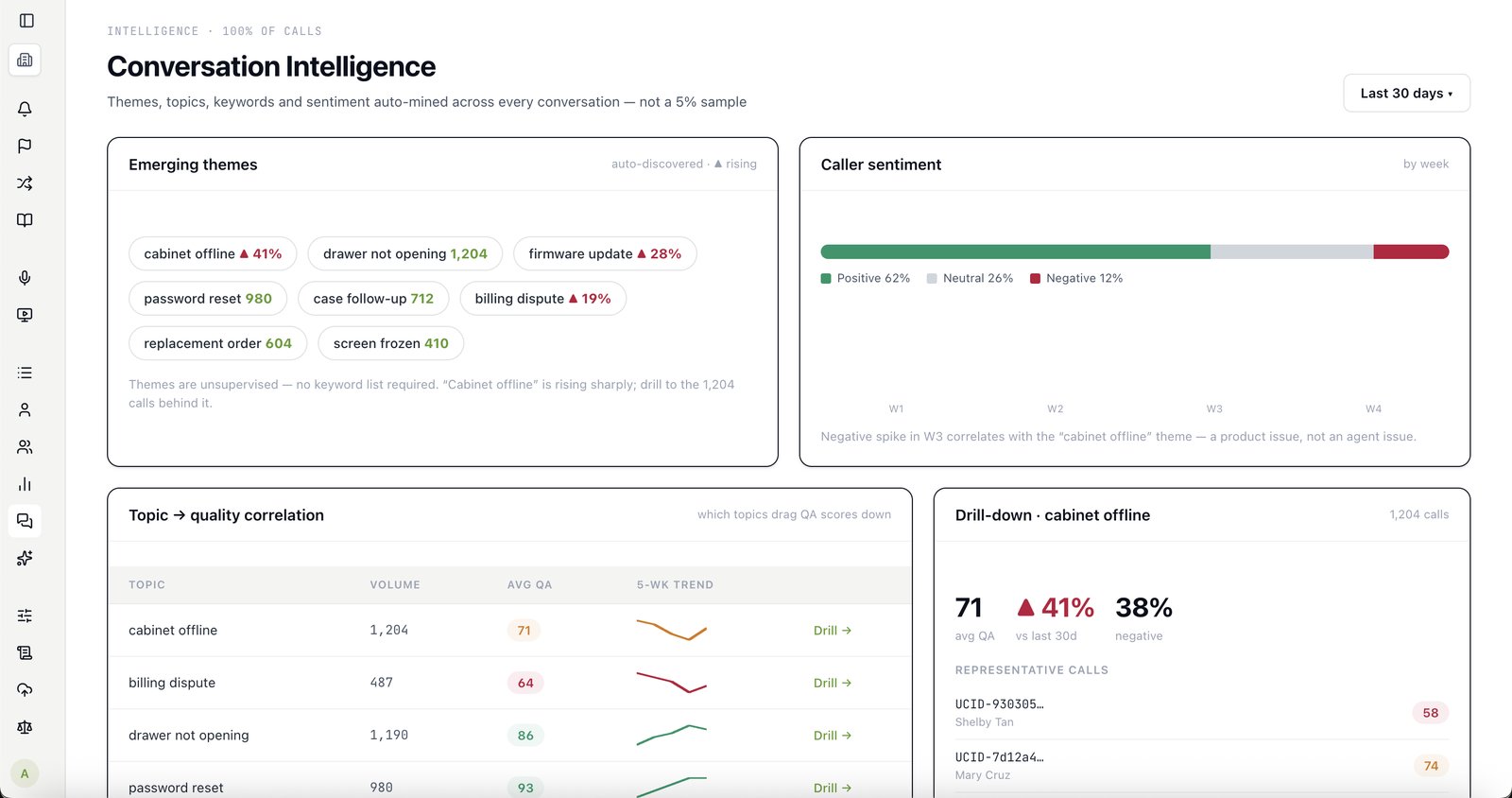
Both. Primas is AI call center quality assurance software — it scores 100% of your calls against your own rubric, with a defensible confidence score on every one — and conversation intelligence software: it analyses every conversation for the risks, compliance gaps and coaching signals a 5% manual sample never sees. One platform, on your existing telephony, with the rubric and your data staying yours.
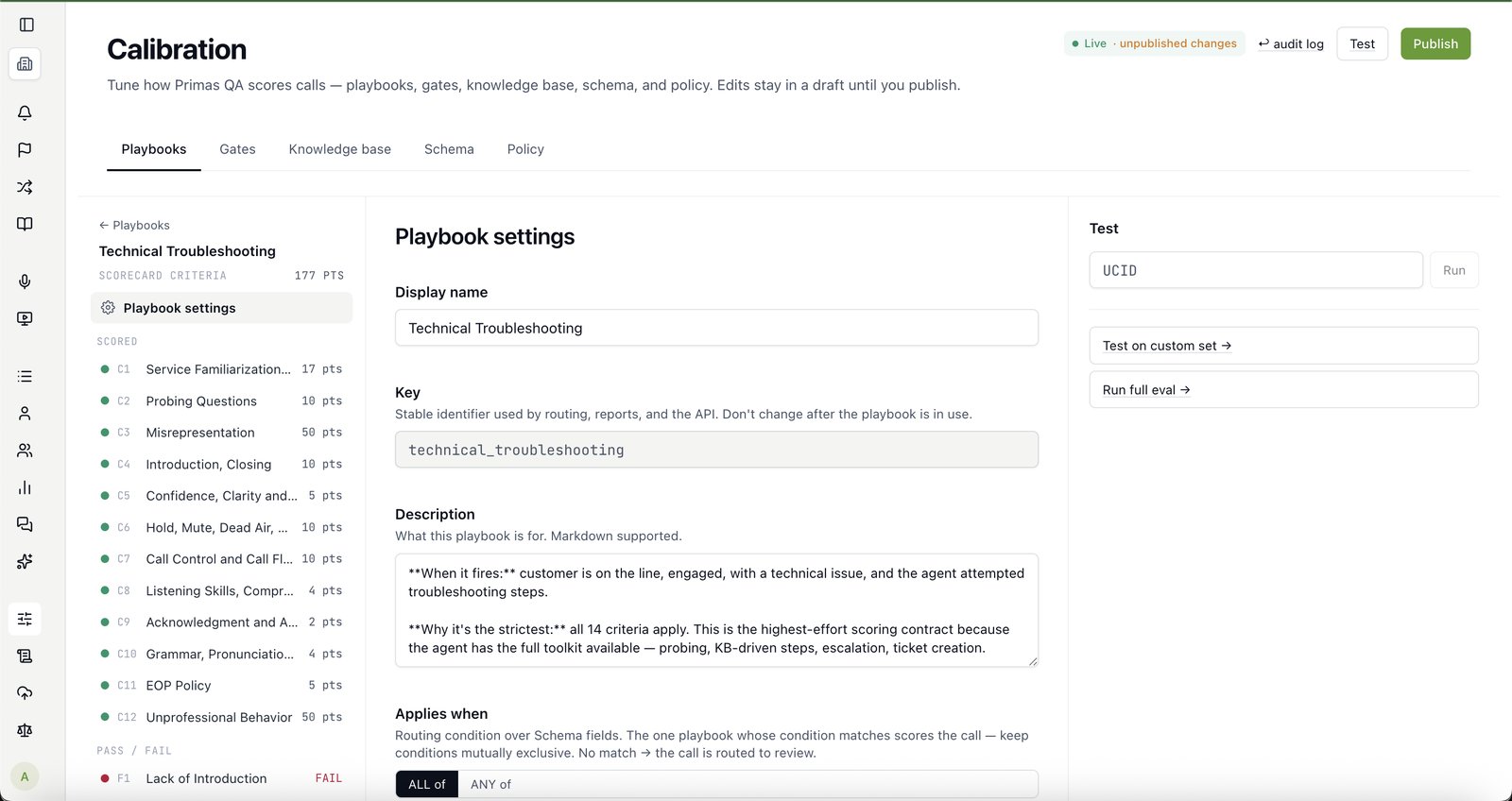
Is it scored against my rubric, or yours?
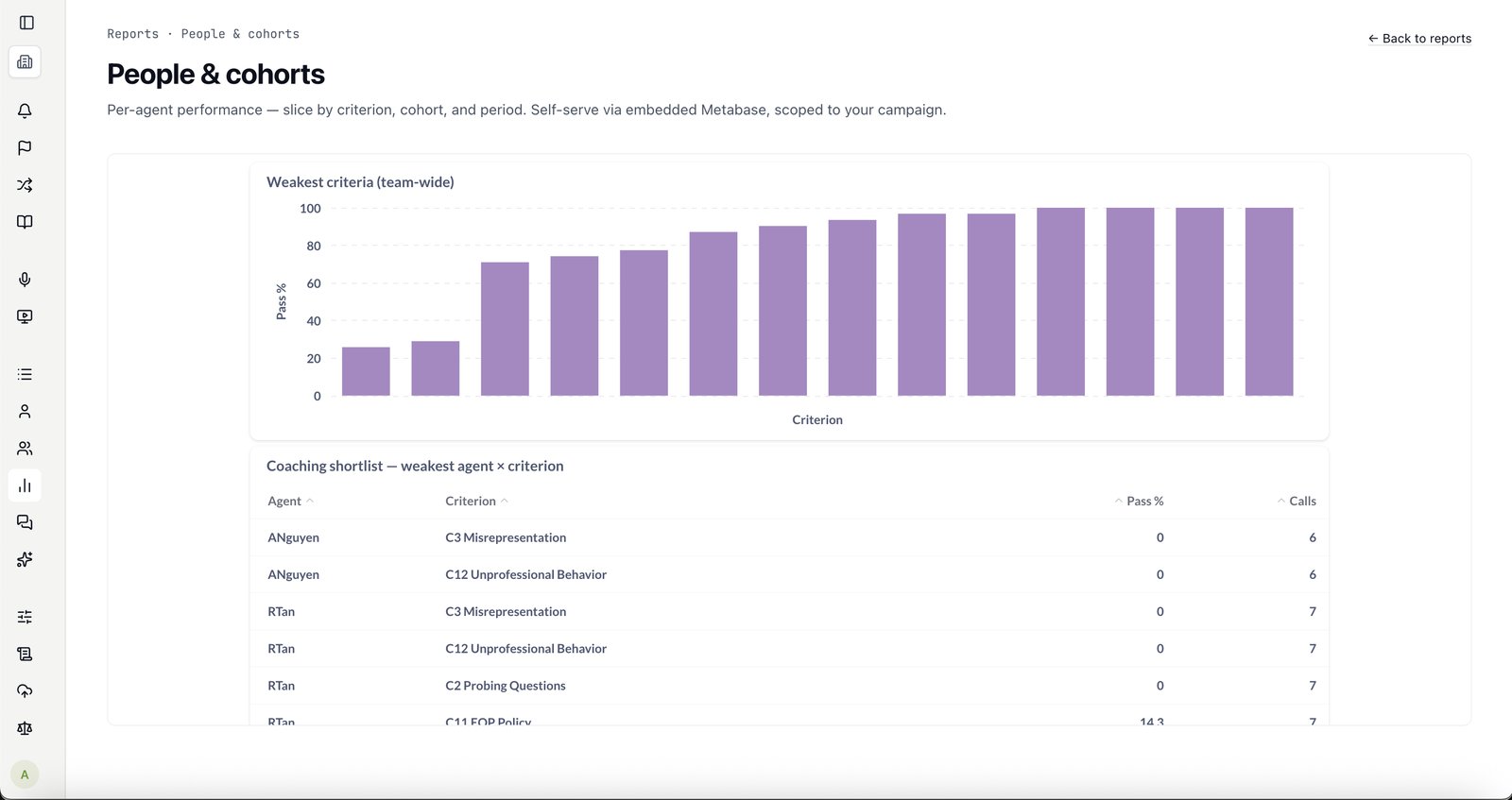
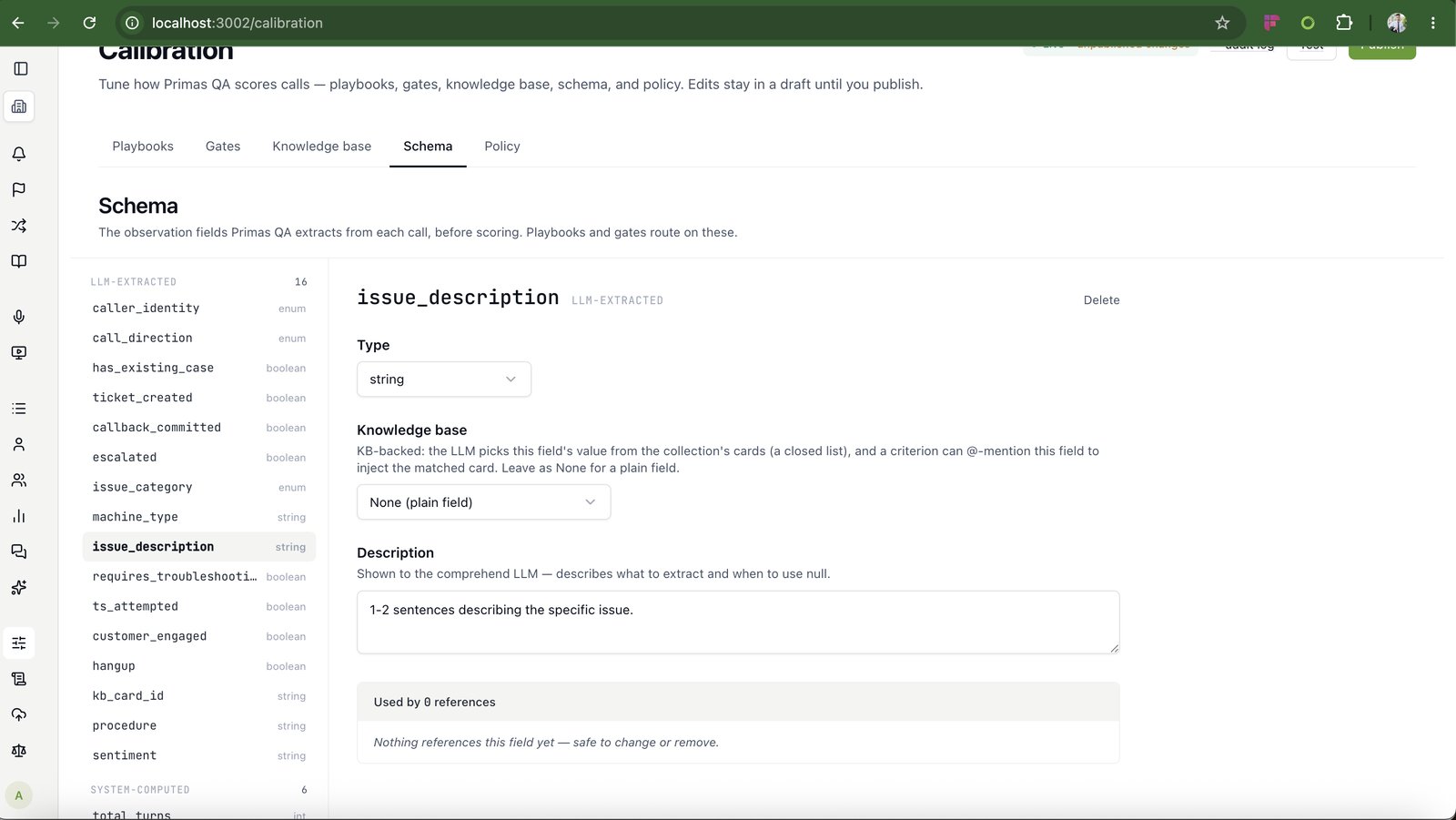
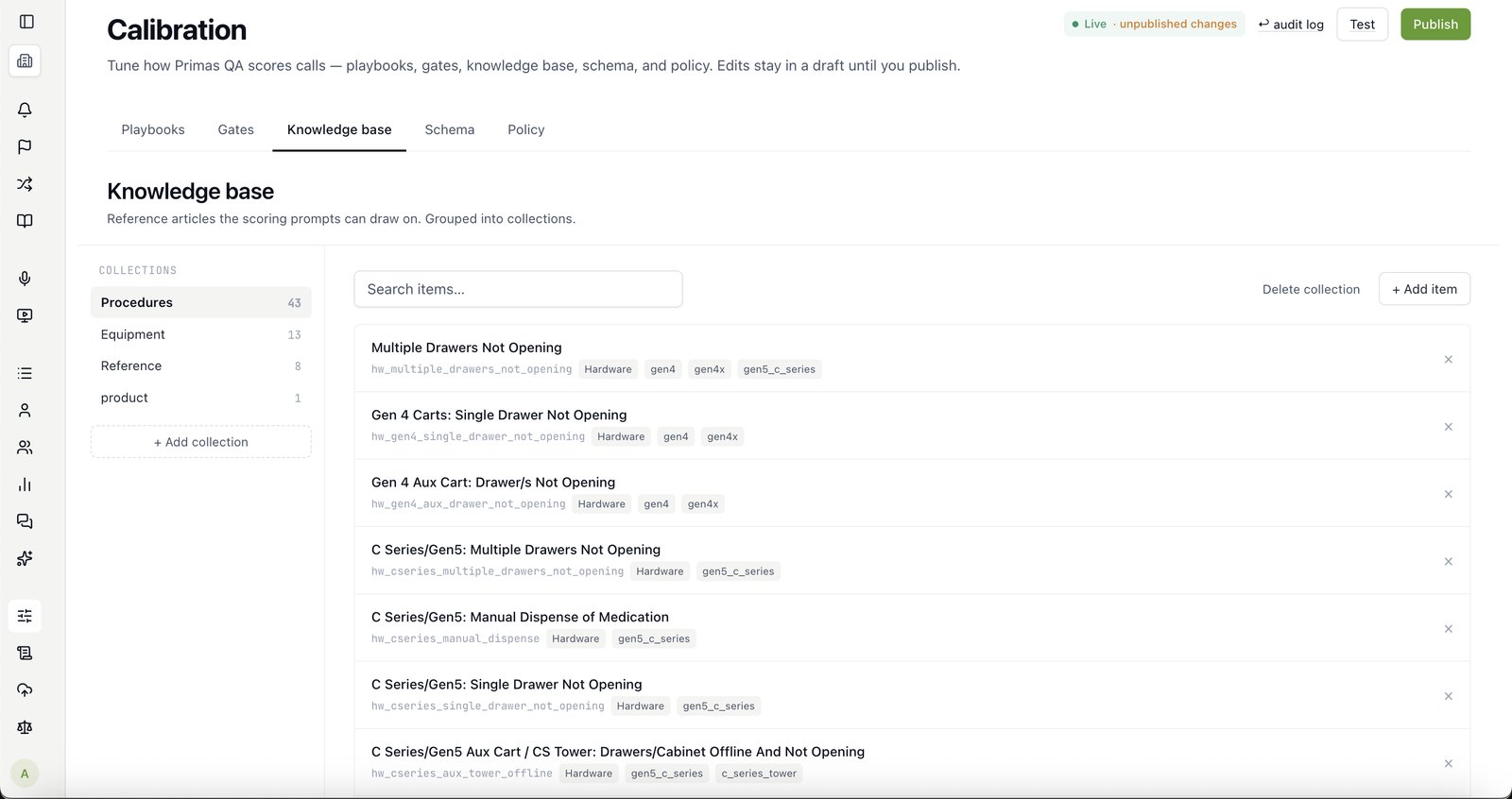
Yours. Professional Services calibrate it on your real calls and your criteria, then hand the rubric to your team — you own it and edit it in-app.
How does an override actually improve the system?
Every override and supervisor note is captured as a signal. Signals aggregate into recommendations with the originating calls cited; your rubric team applies or dismisses each, drafts run against an audit set, and only changes that hit ≥85% auditor-AI agreement publish — versioned, with rollback.
Does my call data leave my environment?
No. Recordings, scores, transcripts and the audit trail stay on your infrastructure. PII never leaves your hardware. No SaaS sits in the middle of your customer data.
Does it run on my existing Avaya, Cisco, Genesys or Vicidial?
Yes — it plugs into your existing telephony; your recordings stay where they are. No rip-and-replace.
How fast can we go live?
~30 days from signed SOW to a live scored batch with confidence routing. Implementation is milestone-paid against acceptance criteria — not on signature.